Alerting
Alerts notify system operators when certain important events occur or a valuable state is reached in any part of a distributed IoT solution. They make sure operators notice what they should notice without going around the system for periodic checking.
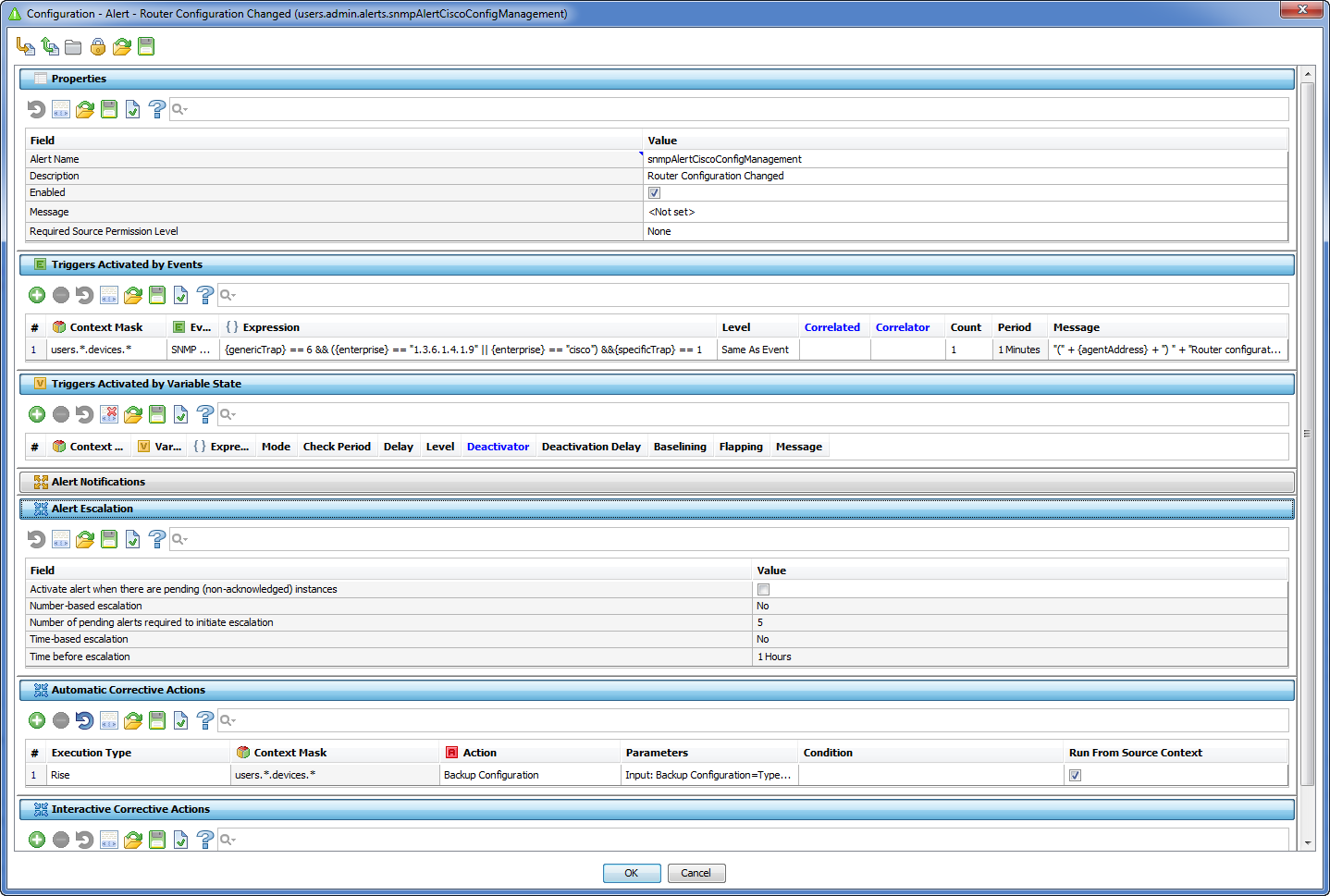
An alert comprises:
| Triggers | Escalation Rules |
| Notification Rules | Corrective Actions |
Alert Triggers
Every alert has one or more triggers defining when to raise it. These can be either event triggers or state triggers.
Each trigger may check one or more devices or resources, e.g. all devices in a group. Combined with the ability to set up multiple triggers per alert, this allows very flexible setup.
Event Triggers
An event trigger is raised when an event of a particular type conforms to the trigger condition. This condition is flexibly configured by an expression, allowing complex checking. For example, a vehicle monitoring system may generate an alert if the "impact" event received from a vehicle controller indicates that the impact strength exceeds a threshold.
Event triggers have support for event correlation, allowing an alert to be activated by the event of one type and deactivated by the event of another type (correlated event).
Any event trigger might be configured to activate only if a sequence of similar events occurred within a certain time frame.
State Triggers
A state trigger can either be raised in response to a certain state, or to any change in the state of whatever is monitored. A state trigger periodically checks the specific variable's value (also pointed by a custom expression).
State triggers have configurable hysteresis (deadband) time for activating the alert only if the condition lasts longer than the certain time period. For example, a state trigger may raise an alert if the temperature rises over 120 degrees for more than 3 minutes. Separate rearming hysteresis is also supported.
Conditions of state triggers may be checked against dynamically adjusted baselines, such as monthly average or weekend maximum. Plus, state triggers support value flapping (frequent change) detection that is reported as a separate alert type.


Notification Rules
Alert notifications inform operators about the alert conditions and provide related information. Notification types include:
- Pop-up messages to the operator (may also prompt for acknowledgment)
- Custom sounds
- E-mail notifications. Alerts may be acknowledged by replying to notification e-mails
- SMS notifications
- Any other notification delivery methods, such as sending a Skype or WhatsApp message via an external application
Besides, alert's corrective actions may implement any other notification schemes.
Active Alerts
Once raised, an alert may remain active while its causing condition is in force or until an event correlated to the activation event is received. The server keeps the global active alert list and tracks active instances associated with every resource and device. Active alerts with high priority are usually visualized on the system overview dashboards.
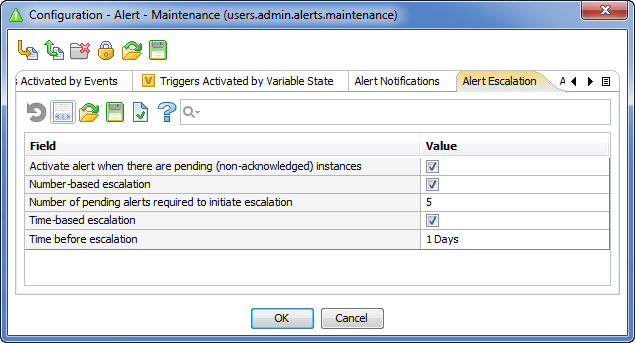
Pending Alerts and Alert Escalation
Some alerts require acknowledgments. Non-acknowledged alert instances are called pending alerts, and such alerts are highlighted to attract operator's attention.
Alert escalation usually indicates that the situation has become critical. Escalated alerts are highlighted in red. There are two possible rules for escalating alerts:
- Quantity-based escalation occurs when a number of non-acknowledged pending alerts exceeds a certain threshold
- Time-based escalation is activated when one of pending alert instances is not acknowledged within a certain timeframe
Both escalation types may be combined for a single alert.
Corrective Actions
When a certain error occurs, it often requires one specific remedy. For example, when available memory on a device becomes low, its internal database must be downloaded or purged. This is always the case – it’s never another action, such as turning the device off or running a servo.

Because of it being so predictable, it can be automated. Any system action that is available in the user interface may be automatically launched in response to an alert.
If no operators are on duty or system functions are in standalone mode, the corrective action launched is "non-interactive" (also called "automatic" or "headless"). There are also "interactive" corrective actions which require operator's input in real-time.
Some interactive corrective actions:
- Starting a custom operator-driven incident resolution workflow
- Running a database purge, asking the operator first: "Are you sure?"
- Rebooting a mission-critical device only after getting confirmation from the operator
Some automatic corrective actions:
- Preparing a status report about the device causing an alert and sending it by e-mail
- Executing an external application that fixes the problem
- Creating a new ticket in the Service Desk system