Models

Models are used to create digital twins of different assets, services, processes, facilities, and environments.
The models range from simple, such as the CPU Load model, to really complicated ones, e.g. representing a whole energy generation facility within a country-wide business intelligence system. The models can also enrich existing system components with new properties, operations, events, and behavior.
Combined with other pieces of AggreGate data mining technology (such as Machine Learning or Complex Event Processing), models allow to predict behavior of their real-life peers for further optimizing their structure and lifecycle.
Each model comprises:
- Definitions of variables representing model values
- Definitions of functions that instruct the model to perform some processing or calculation
- Definitions of events the model can produce
- Definitions of bindings that tie model's properties, operations and events together allowing it to react to other objects' events or states
- Sets of business rules for decision-making according to a machine-readable knowledge base

Model Types
A model can act on its own (absolute model) or get attached to lower-level objects, such as devices (relative model). In the second case, multiple instances of a model are created, each of them using the object it's attached to as its primary data source.
The third model type assumes explicit on-demand model instance creation. For example, an Oil Rig model may hold information about devices and controllers installed on a rig, as well as data collected from the particular rig (that's not a single device indeed). Such models are called instantiable models.
Model Example
Simple monitoring systems allow direct visualization of values that were collected from devices. However, devices from different manufacturers use differing approaches for providing values with the same physical meaning.
For example, network management products are used to track the CPU load of network nodes. This simple metric is available in many different forms:
- Windows-based computers expose "spot" values of the CPU load via SNMP.
- Same Windows machines can provide WMI-based CPU load readings if SNMP is not available.
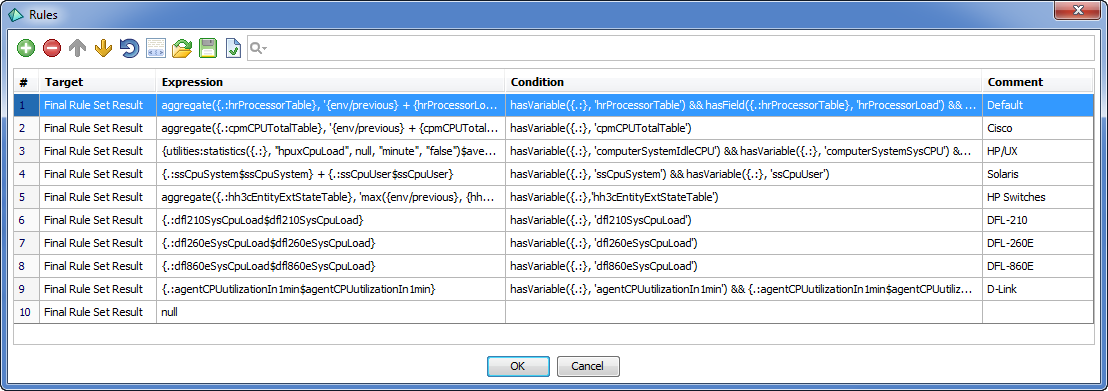
- Cisco routers provide pre-calculated CPU utilization data as 5-minute and 1-hour averages.
- HP-UX servers have counter-type values showing how many seconds the CPU has been busy since the server startup. These counters require complex processing to calculate the current load.

However, a Network Device Dashboard should have a "CPU Load" chart equally looking for all device types. A "High CPU Load" alert is also expected to behave similarly. Moreover, we'd like to build a "CPU Load Overview" report showing the current utilization of all devices in the network.
The right way to ensure the above requirements is having a numeric "CPU Load" metric in every device that provides CPU data. This metric should have the common format, but its calculation and update policy will differ depending on device types.
Using a relative model attached to all network device accounts solves the case. The model has the CPU Load variable definition, a rule set enabling automatic choice of the "right" CPU load information source, and a periodic binding connecting the rule set to the variable.